第三章 從使用工具到建立資源:語料、檢索與雙語平行資料
前兩章的重點放在電腦輔助翻譯工具(computer-assisted translation tools, CAT tools的操作,以及譯者如何在既有的工作介面裡提升效率。本章將拓寬探討範疇:譯者不只是在工具裡工作,也可主動建立自己的參考資源、檢索環境與可重用資料。當譯者開始累積雙語例句、整理舊譯稿、處理雙語網站、對齊中英文段落,原本零散的參考材料就會逐漸轉化為真正可回收、可檢索、可驗證的翻譯資產。
對譯者而言,這種轉變很重要。因為翻譯工作的困難,往往不在於「看不懂原文」,而在於「如何在特定領域、特定語境、特定語區(locale)下,選出最合適的譯法」。這時候,快速找到可信的雙語例句、比對相近文脈、觀察常見搭配,往往比單靠個人語感來得可靠。語料與雙語平行資料的價值,就在於能把「我好像看過這樣寫」轉化成「我知道這種寫法在哪些文本裡一再出現過,因此它是客觀正確的」。
本章分為六節。第一節先介紹公開平行語料庫(publicly available parallel corpora),說明這些資源如何幫助譯者查找譯例與建立判斷。第二節從關鍵詞檢索(keyword search)、雙語對照查詢(bilingual concordancing)一路談到正規表示式(regular expression, regex),讓讀者具備足夠的搜尋能力,能從大量文本裡檢索出有用的例句。第三節進一步談如何自行建立雙語平行資料(parallel data),包含資料來源、整理原則與前處理(preprocessing)思路。第四節說明雙語對齊(bitext alignment)的基本概念,讓讀者理解平行資料不是憑空出現,而是經過一連串選擇與判斷才形成。第五節再把這些資料接回 CAT 工作流程(workflow),讓語料不只是「參考」,而是能進入日常工作流程的資產。最後,第六節以 AI 代理人(AI agent)作為延伸討論,說明未來譯者可能如何用代理人協助蒐集、清理、對齊與整理資料。
如果要用一句話概括本章的核心觀念,那就是:譯者不只是工具的使用者,也可以是語料資源的建造者。當譯者開始建置雙語資料基礎設施,工作方式就會從「每次都重新開始」逐漸轉向「在既有資產上持續累積自身價值」。
1 第一節 公開雙語語料庫如何幫助譯者
「語料庫」(corpus; 複數 corpora)這個詞,聽起來有點學術,但對實務譯者來說,可以用一個簡單的方式理解:語料庫就是一批可系統性檢索的文本。若這批文本只有單一語言,就稱為單語語料(monolingual corpus);若同一批內容在兩種語言之間存在對應關係,就形成雙語語料(bilingual corpus)或平行語料(parallel corpus)。其中對譯者特別有幫助的,是那些可以同時看到原文與譯文、或至少能在兩種語言間進行對照查詢的資料。
公開雙語語料庫之所以有用,不是因為這類資源能自動告訴你唯一的正確答案,而是它能提供「經驗證據」。很多翻譯問題表面上看起來像是詞彙如何對應,但實際上還要考量其文體、領域、語區與用途等。以英文的 policy 為例,在不同脈絡裡可能譯作「政策」、「原則」、「規範」、「辦法」或「保單」。若只查字典,將會得到一串的定義作為可能選項;但若查雙語語料,則可觀察到在公部門文件、保險條款、軟體介面、企業內規中最常出現的是哪種譯法。這種來自真實文本的對照,對譯者的判斷特別有價值。
公開語料庫最直接的用途,至少有四類:(1)查找譯例。在不確定某個固定詞語搭配如何處理時,可以先找相近句型,參考既存譯例,再見賢思齊。(2)觀察語感。此處的語感並非抽象的「行文流暢度」,而是某個領域中,母語使用者或專業機構通常怎麼說。(3)比對表達方式。同一概念在政府文件、新聞、產品說明與學術文本中的措辭可能完全不同,雙語語料能協助譯者快速辨識文體差異。(4)建立穩定性判斷。若某個譯法只在單一網站出現過一次,參考價值就有限;若某個譯法在多個來源、相近文脈下反覆出現,就比較值得納入自己的翻譯決策。
在公開的平行語料資源中,OPUS 是很值得譯者認識的一個入口。OPUS 網站(Open Parallel Corpora, 公開平行語料庫,網址: https://opus.nlpl.eu)長年彙整各種可公開取得的平行語料與多語資料。截至 2026 年初,其官方首頁顯示已收錄超過一千個語料集、超過一千種語言,以及上千億級的句對。雖然這個數量本身不代表品質一定好,但至少說明了一件事:譯者若學會搜尋與篩選,其實可以接觸到遠比過去多的雙語材料,有助於擴大其翻譯的視野與能力。
Opus Corpus 首頁
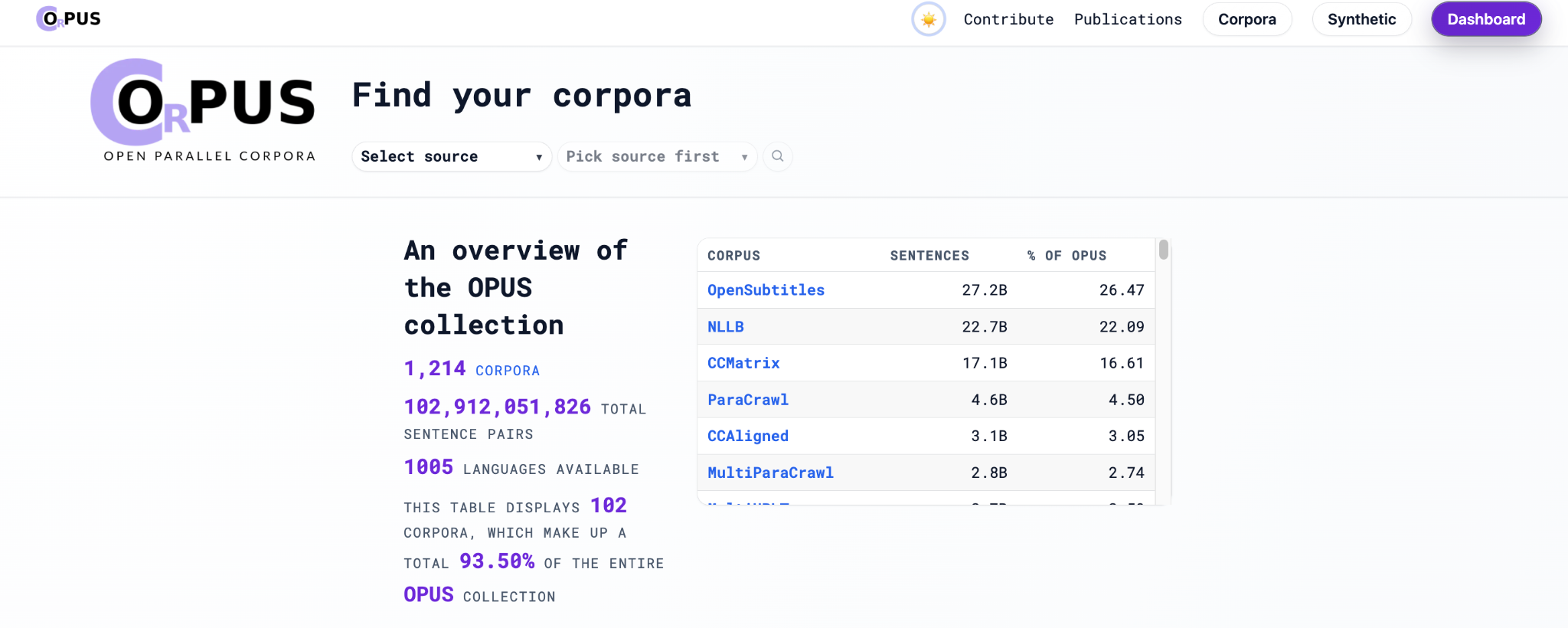
OPUS 的優點,不只是量大,也在於來源多樣。其收錄的語料包含字幕、技術文件、開源軟體在地化資料、政府與國際組織文件、新聞評論、教育內容等。這代表譯者不必只停留在「有沒有例句」的層次,而是可以進一步問:「這些例句來自哪種文本?」「是否符合我的領域需求?」「是否接近我要交付的文體?」例如在翻譯口語對話、影視字幕或遊戲文本時,字幕型語料可能比法律文件更有參考價值;反之,若在翻譯技術說明、使用者介面或開發者文件,像 Mozilla、MDN Web Docs 這類來源就可能比電影字幕有用。
然而,譯者使用 OPUS 或任何公開語料庫時,最重要的不是「找到很多例句」,而是「知道該怎麼懷疑」。公開語料的品質參差不齊。有些資料來自人工翻譯,有些來自眾包、有些可能含有機器翻譯痕跡,有些則是在文件對齊或句子切分時產生噪音。尤其是大規模網路抓取型語料,雖然數量龐大,卻常混入不完整句段、標題殘片、導覽列、日期、版權宣告,甚至錯誤配對的內容。這些問題若未經過濾,就可能把譯者帶向錯誤結論。
因此,譯者應把語料庫視為證據來源,而不是權威裁判。好的使用方式通常包括幾個步驟。首先,先確認語言方向(language direction)與語區是否合適。英文對中文的語料不見得就適合台灣讀者,仍需進一步區分是zh-TW、zh-HK 還是zh-CN。其次,要看資料的來源性質,例如政府網站、博物館、技術文件、字幕、論壇的文體差異都很大。再者,不要只看單一句子,要看同類例句是否穩定重複。最後,最好交叉比對兩到三種來源,避免單一來源的風格偏誤影響判斷。
對譯者來說,公開語料庫真正的價值往往不在於「直接拿來用」,而在於「協助縮小判斷範圍」。在先從語料觀察到三種常見寫法,再回顧客戶的風格指南(style guide)、既有翻譯記憶庫(translation memory, TM)、參考資料與專案語境後,譯者即更容易做出一致而有根據的選擇。換句話說,語料庫不是要取代譯者,而是要協助譯者在資訊不足情況下做出較合理的判斷。
對照查詢的實務場景也很常見。例如在公共政策或外交文件中,promote、advance、enhance、strengthen 這幾個動詞雖然都可譯作「推動」、「提升」、「強化」,但各自常搭配的受詞與語氣仍有差異。公開雙語語料能幫助譯者在這種細微處做出較不武斷的判斷。
另一個常受到忽略的優點,是語料能幫助譯者判斷「不要怎麼翻」。多數情況下,導致譯文顯得生硬的主因並非嚴重誤譯,而是受限於原文句法生硬套用至中文。若透過雙語語料觀察某個英文結構在中文裡通常如何重組,便能更清楚哪些語序為中文慣用、哪些只是看似忠實,但實則僵硬。這也是為什麼語料對譯者有時比字典更有用:字典僅提供對應詞,語料則呈現實際用法的情境。
然而公開語料也有其侷限:(1)公開語料未必能反映最新的品牌、流行用語以及語言習慣;(2)這類資源常缺乏脈絡細節,不知道某個譯法是在什麼任務條件下產生;(3)公開語料可能混入不同時期、不同翻譯規範與不同品質等級的文本。這些限制提醒我們,語料庫不能直接取代客戶指示、既有術語庫與專案內部資源。但在沒、有內部資源、需要快速建立判斷時,公開雙語語料仍然是譯者極具成本效益的外部輔助工具。
如果把公開雙語語料庫的功能濃縮成一句工作原則,那就是:先用公開語料擴大視野,再用專案規範收斂答案。譯者真正需要的不是海量文本本身,而是從海量文本中抽出與當前任務最相關、最可信、最接近目標語區的那一小部分。
2 第二節 文本檢索與資料處理技術:對照查詢與正規表示式
語料之所以有用,前提在於能有效檢索所需資訊。大量文本若不能有效搜尋,充其量只是一堆資料。對譯者來說,搜尋語料最基本的能力不是寫程式,而是知道怎麼把「我想找某種句子」轉換成可執行的檢索條件。這就是關鍵詞檢索、對照查詢與正規表示式要解決的問題。
最簡單的檢索是關鍵詞搜尋。輸入一個詞或片語,系統便將含有該字串的句子篩選出來。此檢索方式雖直觀,但成效受限。因為翻譯問題往往不是「某個詞出現在哪裡」,而是「某個詞在什麼上下文裡如何表達」。這時候,單純的搜尋結果還不夠,需要進一步做對照查詢,也就是把關鍵詞放回上下文裡觀察。常見的呈現方式關鍵詞索引顯示」(keyword in context, KWIC),亦即讓關鍵詞出現在頁面中央,左右兩側保留前後文,以利快速掃描搭配詞、語氣與句型。
對照查詢的核心價值,在於能把「語言單位」放回「語言環境」。譯者很少只翻一個詞,而是翻一個出現在特定句型中的詞。例如 account 不一定都是「帳號」;在會計文本裡可能是「帳戶」,在敘事語境裡可能是「敘述」、「說法」。若只查閱字典,很容易被高頻義項誤導;若觀察 concordance line,便能了解這個詞與哪些動詞、介系詞、修飾語反覆出現,進一步判斷這個詞在目前文本中的功能。
這種檢索能力,不必依賴昂貴平台才能做到。傳統的「對照檢索軟體」(concordancer1)可以勝任,很多日常工具也可以部分完成同樣的工作。以 Calibre 的 ebook-viewer 為例,這套工具原本是電子書閱讀器,卻很適合被譯者挪用為中小型語料檢索介面。官方文件指出,ebook-viewer 不只支援一般搜尋,也支援 whole words、nearby words 與 regex搜尋模式,並提供 Reference mode 方便定位段落,以及 highlight 與 annotation 功能協助做人工標記。若將整理好的雙語文件或單語參考資料做成 ePub、或匯入為可閱讀文本,calibre 其實能成為相當順手的例句檢索工具。
Calibre Regex 工具使用方式
工具 (1):⇒ [Ruben] Itemize the following steps
Calibre 為一開源 (open source)電子書及文件格式轉換軟體,內建電子書閱讀器。下載網址:https://calibre-ebook.com/download
選擇適合作業平台的版本:
- 安裝完成後可在 Explorer/Finder 內在檔名上按右鍵,再點選 ebook-viewer 可將文件打開。例如,Alice in Wonderland (《愛麗絲夢遊仙境》) 一書可以在古騰堡計畫 (Project Gutenberg) 網站下載:https://www.gutenberg.org/ebooks/11

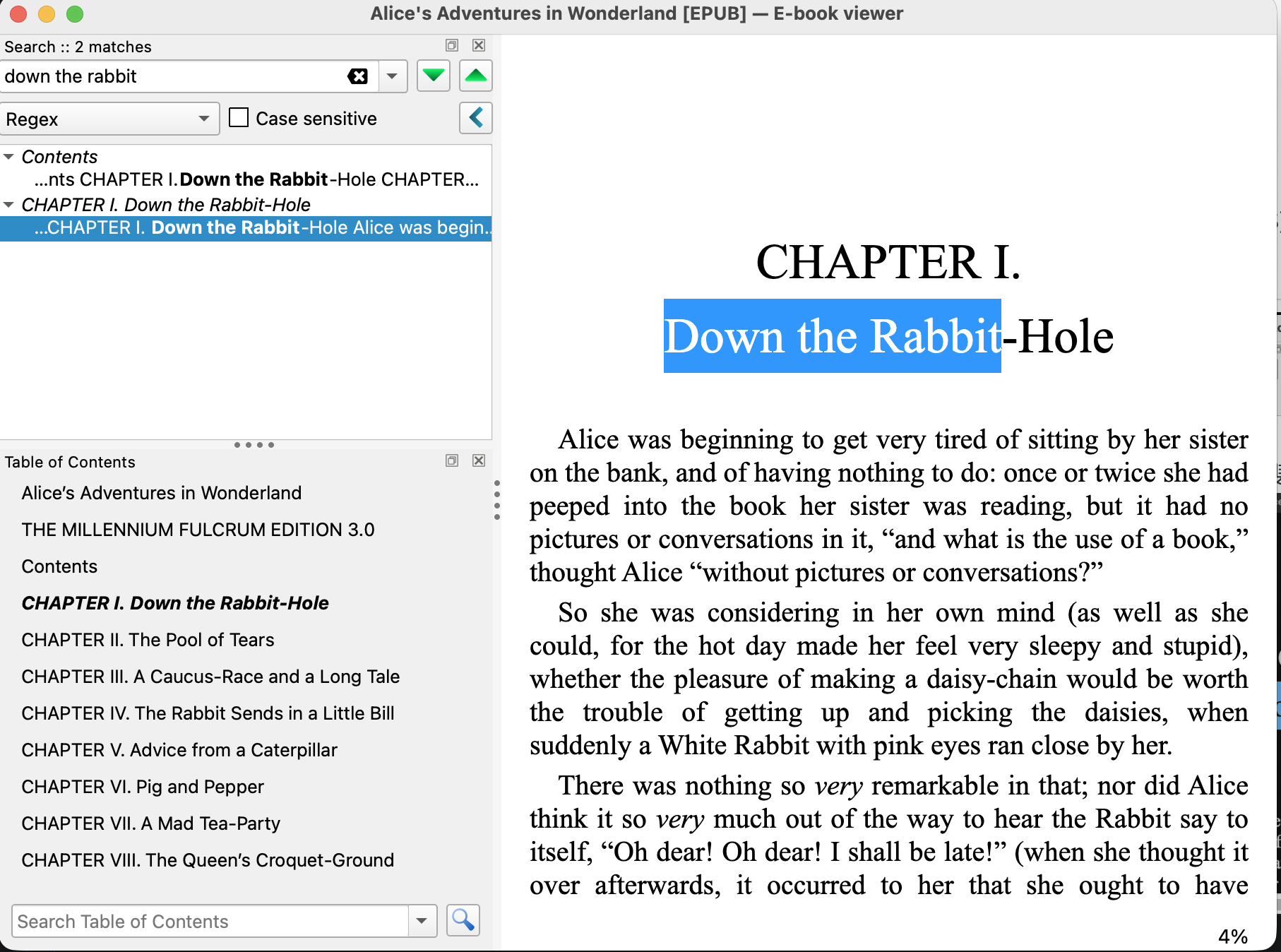
Ctrl-F (Windows) 或 ⌘F (macOS)可進入搜尋。搜尋方塊下方的下拉式選單中可點選以 regex 搜尋。

輸入 down the rabbit 可以搜尋到2筆:目錄及第一章的標題。
同樣地,許多支援正規表示式搜尋的文字編輯器,也能扮演輕量 concordancer的角色。例如 VS Code、CudaText、Zed、Sublime Text等,都可以對單檔或整個資料夾做全文檢索。對譯者來說,這很有用,因為實務上的目的並非進行大型語言研究,而是要在一批已知資料裡快速找到某種形式的句子、標記或對應模式。若資料來自一套雙語網站、一批舊譯稿或特定客戶過去的中英對照文件,那麼文字編輯器加上 regex,通常便足以解決多數問題。
Regex 工具 (2):Zed (開源文字編輯軟體;下載網址:https://zed.dev/)
安裝完成後可以編輯純文字檔案 (.txt)。按下 Ctrl-F (Windows) 或 ⌘F (macOS) 顯示搜尋方塊,再按下 .* 圖示進入 regex 搜尋模式。
關鍵詞檢索、對照查詢與 regex 的關係可以如此理解:關鍵詞搜尋是找字串,concordancing 是看上下文,而regex 係將搜尋條件表達得更精準。當檢索需求從「找這個詞」變成「找所有帶有百分比與括號的句子」、「找所有未翻譯的英文字串」、「找所有第 X 條、第 X 項」,甚至是如「戚戚然」、「營營役役」的疊詞時,regex 就會變得非常有用。
下載《李清照集》(https://www.degruyterbrill.com/document/doi/10.1515/9781501504518/html)英譯 ePub 檔,以 Calibre ebook-viewer 搜尋 regex: (\p{Han})\1(\p{Han})\2 可找到9筆AABB式疊詞:
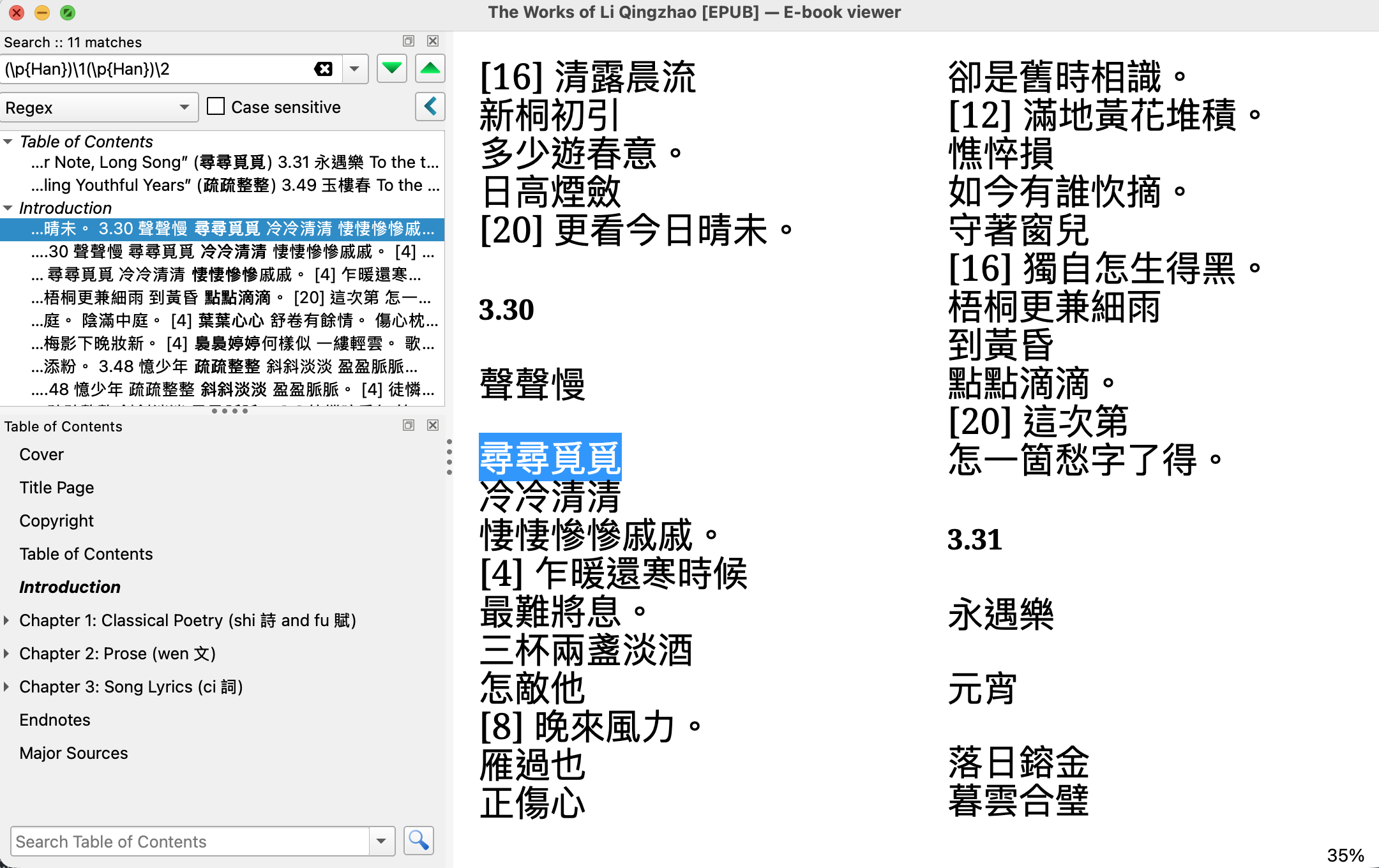
正規表示式本質上是一種在文本中尋找特定文字出現形式、次序或規律(pattern)的語言。正規表示式通常不是在找某一個固定詞(不過一定要如此也可以),而是在描述一類字串長什麼樣子。舉例來說,若欲尋找所有阿拉伯數字,可以用\d+;若欲尋找小數,可以用 \d+(?:\.\d+)?;若欲尋找百分比,可以在後面再接 %。這種寫法看起來像程式語言,但其實只要抓住幾個核心符號,譯者就已經能處理很多工作。
最常用的基本符號,包括幾類。句點 . 代表任意單一字元;星號 * 代表前一個模式可出現零次以上;加號 + 代表前一個模式至少出現一次;問號 ? 代表可有可無。方括號 [] 用來指定字元集合,例如 [A-Z] 表示任一大寫英文字母。脫字符號 ^ 與錢字號 $ 常用來分別表示行首與行尾。\d 代表數字,\s 代表空白,\w 在許多 regex engine中代表英數底線組成的字元。這些基本積木,就足以描述許多譯者常碰到的形式。
3 正規表示式摘要
| 字元 | 意義 / 用法 | 備註 |
|---|---|---|
| 字面意義的字元 (literal characters) |
例如:a b 1 2 _ " < > |
|
| 特殊字元 metacharacters |
||
\t |
tab(定位字元) | |
\n |
newline(換行字元); Windows: \r\n(CR LF)UNIX/Linux/macOS: \n(LF) |
|
\s |
white space(空白字元) | 包含空格(space)及 tab 等 |
.(句點) |
比對任意字元(\n 除外) |
|
| 元字元 (必須以 \ 跳脫才能進行文字比對) |
||
\ |
跳脫 (escape) 字元 | |
| |
替代(或) | |
() |
群組;(?:) 為非擷取群組 |
|
[] |
字元類別;恰好比對一個字元 | 範例:比對任一英文母音字母 [aeiou] |
{} * ? + |
量詞 | |
^ $ |
錨點(零寬度) | |
? |
(1) 作為量詞時,作用於緊鄰其左方的一個字元、字元類別或群組; (2) 作為非貪婪 non-greedy 或懶惰 lazy 指定符 |
|
| 錨點 anchor (零寬度:僅比對位置,不比對字元) |
||
\b |
詞邊界 | 範例:空白字元(或標點符號)與文字字元之間的位置 |
^ |
脫字符號:字串開頭 | |
$ |
錢字符號:字串結尾 | |
| 量詞 quantifier (作用於緊鄰其左方的一個字元、字元類別或群組) |
||
* |
零次或多次 | |
+ |
一次或多次 | 亦即「至少出現一次」 |
? |
零次或一次 | 亦即「可有可無」 |
{n} |
恰好 n 次 | |
{n,m} |
至少 n 次,至多 m 次 | |
{n,} |
至少 n 次,無上限 | |
| 字元類別 | 以 [] 括起的字元 ── 恰好比對一個字元 |
|
| 範圍 | [a-z] 比對任一英文小寫字母;\p{Han}(最完整的寫法)或 [一-龥] 或 [\u4E00-\u9FFF] 或 [\x{4E00}-\x{9FFF}],共 20,992 個基本中文字元 |
起始字元的 Unicode 碼位必須較小;中日韓統一表意文字(CJK Unified Ideographs)涵蓋最常見的 CJK 字元(即漢字);Zed 及 Calibre ebook-viewer 皆可接受;CudaText 使用最後一種格式處理一般 Unicode 範圍 |
| 快捷寫法 | ^ 在 [] 中表示該類別的「相反」(也就是所有此類別以外的字元) |
範例:比對任何非英文母音的字元 [^aeiou] |
\d |
數字,等同於 [0-9] |
|
\w |
「文字」字元;\d 加上 [a-zA-Z] 加上 _(底線字元;underscore),對於非英文字母書寫的語言可能還包含更多字元 |
\w 的定義取決於特定的正規表示式引擎;部分引擎會納入漢字字元及含附加符號的字元(如 é、ç、ü);其他引擎則不會。 |
\D \S \W\P{Han}(相反集合) |
代表對應小寫字元類別之否定的字元類別 | \D、\S、\W、\P{Han} 分別為非數字、非空白、非文字及非中日韓字元 |
例如,若欲找出所有數值加單位的表達,例如 5 km、3.5 GB、20%,可以寫成\d+(\.\d+)?\s?(km|GB|%)。若欲擷取英文術語後面緊接中文括號說明的寫法,例如 Application Programming Interface(API) 或 workspace(工作區),可以針對英文字串與全形括號組合設計模式。這些檢索方式之所以有用,是因為這些模式不是把文字當作一串字,而是把文字當成一種可辨識的形式。
在搜尋方塊輸入:\d+(\.\d+)?\s?(km|GB|%) 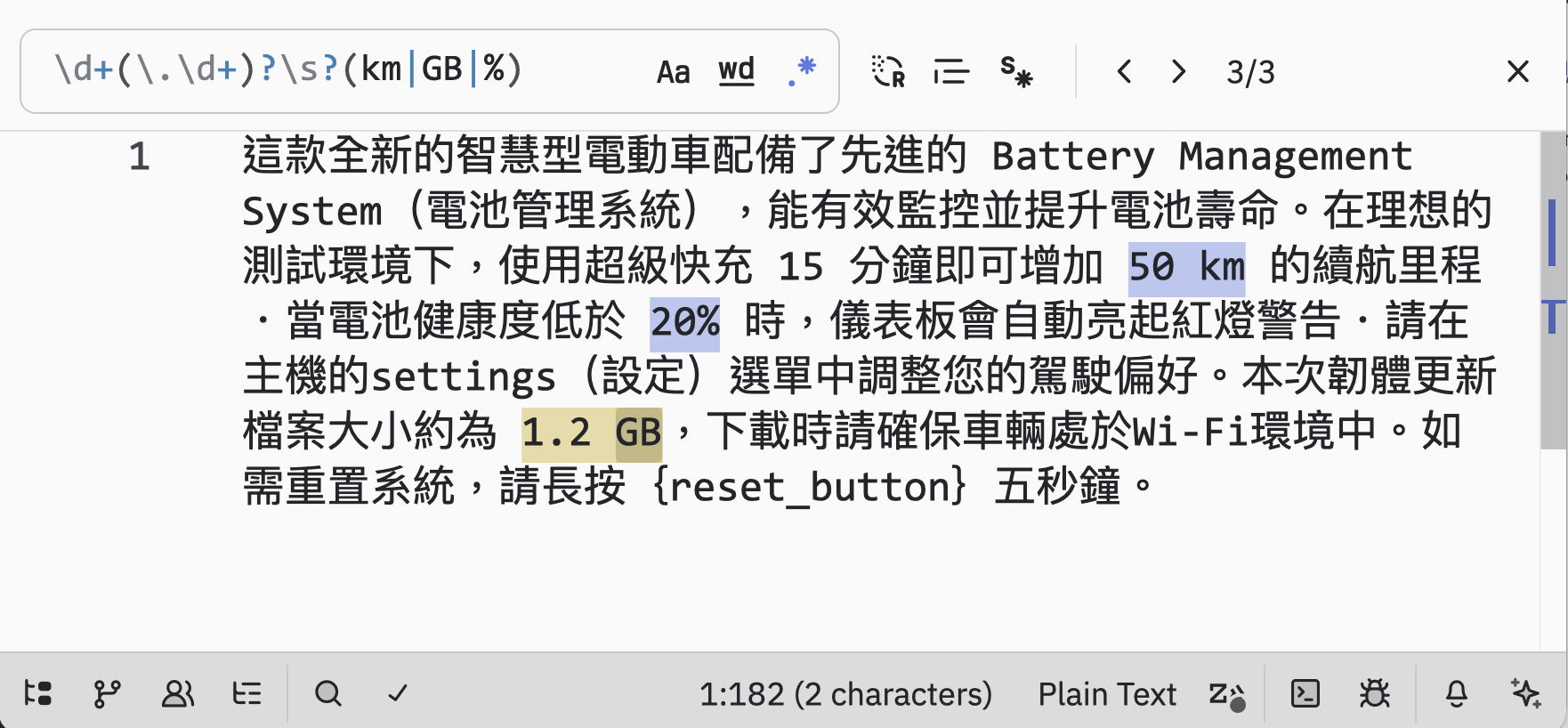
以上可看到符合該 regex 的文字在編輯器中標示出來。此 regex 以3個部分分析如下:
| \d+(\.\d+)? | 數字(1或多個;代表整數部分),後面有「可有可無」的小數點及1或多個數字」 |
|---|---|
| \s? | 空格「可有可無」 |
| (km|GB|%) | 3選1: km 或 GB 或 % |
| 以上為要出現在同一行: 分 3 rows | |
https://colab.research.g oogle.com/drive/1hz8Yt1vev6xmfRnemPzDcyjXkBZ-m7qF | | 選單:先點選 Runtime ⇒ Run all 讓系統下載程式套件及語料庫 (OpenSubtitles 2024) | | 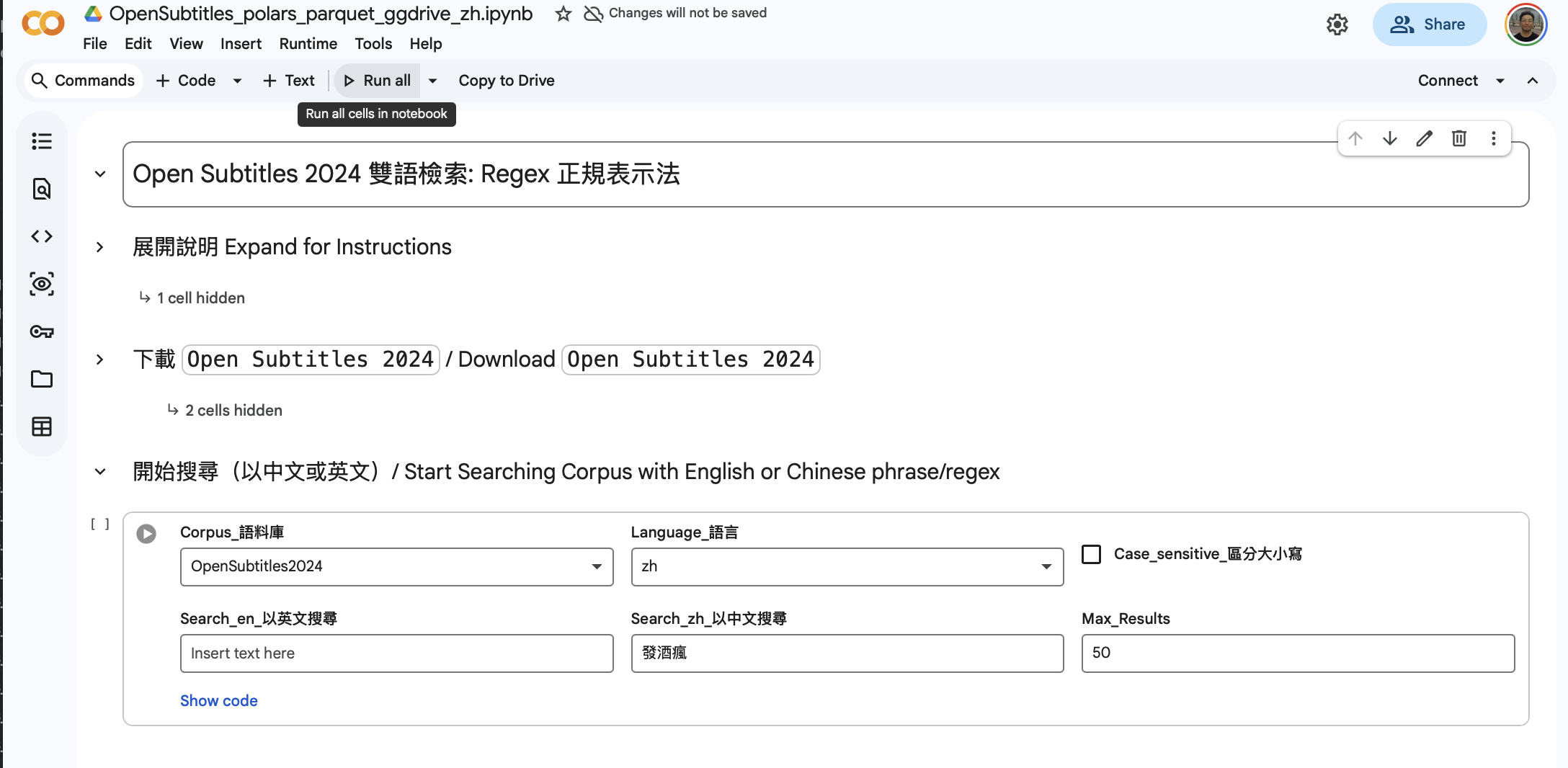 {width=“5.854166666666667in” | height=“3.0in”} | | 因系統 須下載語料庫,故請耐心等候數分鐘。系統完成搜尋後會將結果顯示於下方: | | {width=“5.854166666666667in” | height=“3.0in”} | | 因系統 須下載語料庫,故請耐心等候數分鐘。系統完成搜尋後會將結果顯示於下方: | |  {width=“5.854166666666667in” | height=“2.2222222222222223in”} | 使用者可更改搜尋語言及 字串(中、英字串輸入方格分開)。如要儲存搜尋結果,可先點一下表格,按 Ctrl-A 或 ⌘A (全選), 再剪貼至 Word、Excel 或文字編輯器即可。 | ==========================================================================================================================================================================+ | {width=“5.854166666666667in” | height=“2.2222222222222223in”} | 使用者可更改搜尋語言及 字串(中、英字串輸入方格分開)。如要儲存搜尋結果,可先點一下表格,按 Ctrl-A 或 ⌘A (全選), 再剪貼至 Word、Excel 或文字編輯器即可。 | ==========================================================================================================================================================================+ | |
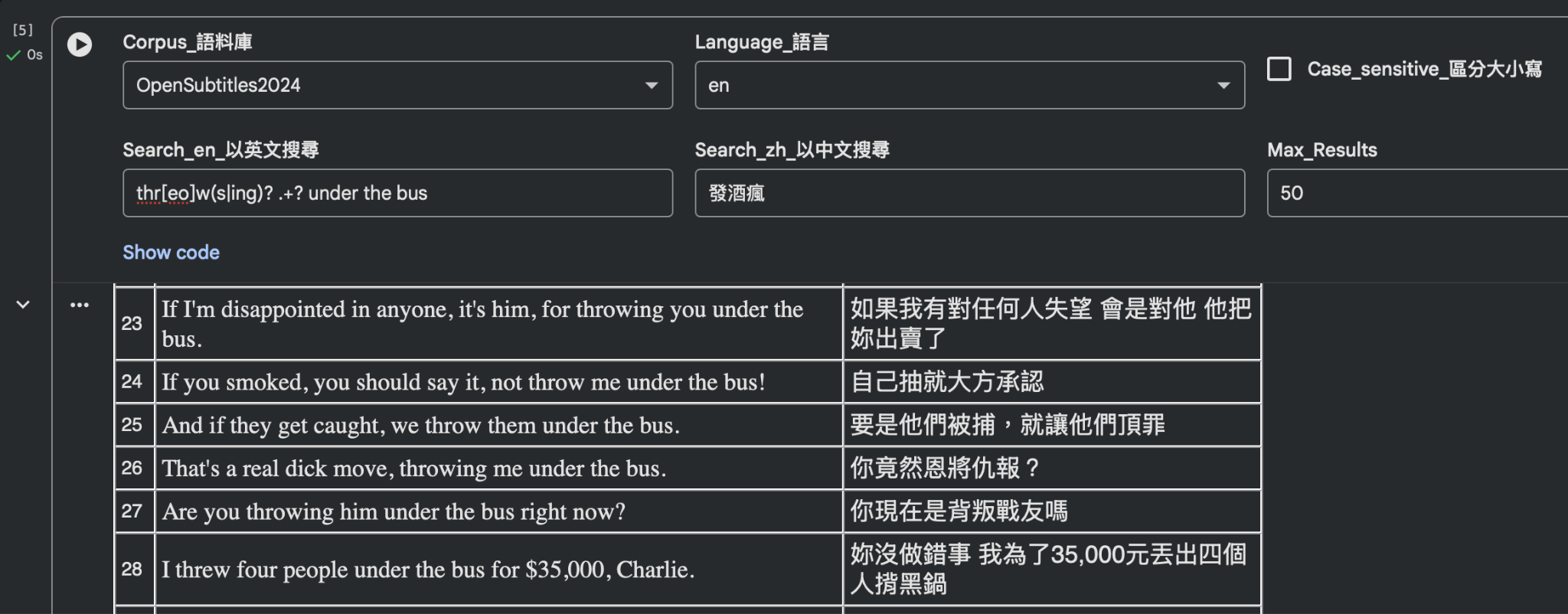
⇒throw <someone> under the bus
例如,輸入英文搜尋字串 thr[eo]w(s|ing)? .+? under the bus 可找到
… throwing you under the bus. … throw me under the bus! I threw four people under the bus for $35,000, … 等等
對譯者特別重要的,是正規表示式在品管與前處理上的用途。很多雙語資料在進入對齊或TM之前,都需要先過濾雜訊,如頁首頁尾、重複空白、編號殘片、複製貼上留下的斷行、OCR造成的錯字、HTML標記、網址、程式碼片段、電子郵件地址等,若不先處理,後續比對與對齊的品質就會大幅下降。regex 的價值,正在於能快速批次抓出這些形式,免去逐行人工檢查的勞費。
如果說基本 regex是在找形式,那麼進階語法則是在處理「關係」。這裡最常用的是群組(group)、回參(backreference)與前後查找(lookahead與 lookbehind)。所謂群組,就是用括號 ()把某一段模式包起來,讓整段模式成為可重用的單位。舉例來說,(Chapter|Section)\s+\d+可以同時抓到 Chapter 3 與 Section 2。若括號內的內容被捕捉下來,就可以在後續替換時引用,常寫成 \1、\2等。
回參對譯者很實用,因為很多清理工作其實是「把找到的東西重排」。例如,可能從一批資料裡擷取到English Term(中文譯名) 的形式,想改成 中文譯名(English Term)以符合雙語註記習慣。若搜尋模式寫成 ([A-Za-z][A-Za-z0-9 ._-]+)(([^)]+)),那麼替換時便可用 \2(\1)把順序交換。又例如,若欲找出連續重複的標點,如 !!、,, 或 。。,可以用 ([,。!?;:])\1+ 這種帶回參的寫法。回參的本質,是讓regex 不只認得某種字形,也認得「前面出現過的同一段內容」。
另一類很實用的進階語法,是 lookahead 與lookbehind,也就是前後查找。這兩種語法的特色是只檢查條件是否成立,卻不會將該條件納入最終的匹配字串中(non-consuming)。這在譯者處理格式時特別方便。假設只想擷取第12條 中的數字,而不欲將「第」與「條」一併納入,便可使用(?<=第)\d+(?=條)。再例如,欲找出所有後面接全形括號的英文術語,卻不將括號內容一併納入,可使用某種(?=()的前瞻寫法。這種語法的實務價值,在於能協助精確鎖定目標,而不破壞周邊結構。
不過,使用 regex 時一定要記住:不同工具的正規表示式引擎(regex engine)不完全相同。某些編輯器支援 lookbehind,某些不支援;有些工具把\w 視為英數底線,不包含中文;有些則對 Unicode 支援較完整。calibre 的regex 搜尋、文字編輯器的搜尋、程式語言內建的 regex函式庫,彼此的細節也可能不同。因此,實務上最重要的不是背所有語法,而是知道先做小範圍測試。切忌一開始便對整批資料進行大規模取代;應先於少量樣本上確認模式是否精確匹配目標。
———————————————————————————————————————————————————————- https://colab.research.google.com/drive/1hz8Yt1vev6xmfRnemPzDcyjXkBZ-m7qF ———————————————————————————————————————————————————————-
具備這種檢索思維後,很多工作會突然變快。譯者不再僅憑「肉眼尋找」,而是學會構思更精準的搜尋條件。這種能力對建立語料尤其關鍵。因為語料建置的本質,往往不是高難度演算法,而是大量重複的小判斷:哪些行要保留、哪些要刪除、哪些看起來像正文、哪些只是網站噪音、哪些中英片段可能互相對應。regex 無法替譯者做出所有判斷,但仍能把最機械、最耗時的篩選工作大幅自動化。
從這個角度看,regex其實不是工程師的專利,而是譯者的放大鏡。當資料量增加、文本來源變雜、格式問題變複雜時,此工具能幫助譯者看見肉眼不易穩定捕捉的規律。也因為如此,regex不只是「搜尋技巧」,更是語料工作中非常核心的一種整理能力。
第三節 如何自行建立雙語平行資料
公開語料庫很有幫助,但終究不是為特定專案量身打造。譯者若想建立貼近自己工作領域的資源,最終仍要學會自行建資料。這裡所謂的「建立雙語平行資料」,並不一定是指建構龐大的學術型語料庫;很多時候只需把一批原本零散的中英文材料整理成可對照、可搜尋、可匯出的形式。語料規模可以很小,但只要結構合理、來源清楚、品質可控,這樣就已經很有實務價值。
雙語平行資料的來源其實比想像中多。最常見的包括:公開雙語網站、政府與機構的多語頁面、舊專案中已交付且可重用的譯稿、客戶允許使用的雙語文件、翻譯記憶交換格式檔(Translation Memory eXchange, TMX)、掃描後經光學字元辨識(optical character recognition, OCR)處理的對照文件、PDF版年報或產品手冊、電子書與字幕檔、甚至為長期累積的例句資料夾。關鍵不是來源多不多,而是是否能先釐清三件事:第一,是否合法可用;第二,是否符合目標語區;第三,是否值得為這類來源投入整理成本。
在實務上,譯者最容易忽略的往往是權利與用途邊界。不是所有看得到的雙語網站都適合擷取為語料,也不是所有舊譯稿都能任意挪作訓練資料。若資料牽涉客戶機密、付費平台、禁止重製的網站內容,或明顯受到保密協議約束,那就不能因為技術上做得到就直接納入自己的資源。語料工作雖然看似偏技術,實際上首先是一個版權與責任問題。來源若不乾淨,後面整理得再漂亮,也不應作為可重用資產。
若以公開可用的來源來說,雙語網站是非常適合譯者練習建置平行資料的材料。尤其是那些語言切換清楚、頁面結構穩定、同一篇內容有中英版本對照的網站。以台灣讀者較常接觸的情境為例,中文原生、再提供英文版本的網站,常見於政府機關、博物館、觀光與公共資訊站點。例如外交部中英文網站及所屬《光華雜誌》、國立故宮博物院多語網站、其他公部門的雙語頁面,都很適合蒐集中英對照資料。這類文本通常具有正式、機構式、對外說明型的文體,對處理政策、文化、公共溝通與行政資訊特別有參考價值。
反過來看,以英文為原生、再提供中文在地化版本的網站也很有價值。像 Apple Support、MDN Web Docs、Python官方文件等,都是譯者可以留意的來源。這類網站的好處是英文原文通常穩定、版本明確,中文翻譯則有助於觀察技術文件、說明文字、介面指示與操作步驟如何在繁體中文語境下被處理。若工作涉及軟體在地化、技術支援內容、知識庫或教學文件,這些來源往往比一般新聞或字幕更接近實務需求。
值得特別提醒的是,雙語網站不只要看「有沒有中英文」,還要看「是否真的是對應頁」。很多網站雖然有語言切換按鈕,但中文頁與英文頁的內容量並不一致,甚至只共享標題與導覽列,正文已經改寫成不同版本。還有些網站會因語區不同,增刪段落、調整例子、改動圖片說明,甚至更換整個資訊架構。這種情況下,這類網站可以作為比較語料或風格參考,但未必適合直接拿來做嚴格的平行對齊。因此,在蒐集來源時,最好先抽樣檢查十到二十組頁面,確認這些頁面到底是翻譯關係、改寫關係,還是只是主題相近。
自行建置資料時,來源評估可以用一個簡單原則:結構穩定、文體一致、語區明確、對應關係清楚、雜訊可控。這五點比「資料量很大」更重要。因為小而乾淨的資料,往往比大而混亂的資料更能在CAT工作中真正發揮作用。對譯者而言,最理想的情況不是蒐集到十萬組未整理句對,而是累積三千到五千組高可信、附來源資訊、可立即檢索與匯出的平行片段。
擷取資料之後,前處理通常比想像中更花時間。網站資料常見的問題包括導覽列、頁尾、版權宣告、日期、分享按鈕文字、隱私政策連結、breadcrumb、圖片替代文字等非正文內容混入。PDF常見的問題則是頁碼、頁首、換頁斷裂、欄位錯位、字距異常與複製後的亂斷行。掃描檔再加上OCR之後,還可能產生把「l」辨成「1」、把全形標點辨錯、或把一整列文字錯切成多段的問題。這些雜訊若不先清理,後面無論做regex 檢索還是 bitext alignment,結果都會受影響。
因此,建立雙語平行資料時,最實際的做法往往不是一開始就追求自動化,而是先建立穩定的欄位結構。最基本的一張工作表,至少可以有:id、source_url、title、language、locale、date、raw_text、clean_text。若已經知道中英文成對,也可以從一開始就用兩欄或多欄結構,例如en_raw、en_clean、zh_raw、zh_clean。這樣做的好處是,不會在清理過程中覆蓋原始資料;日後若發現清理規則有誤,亦便於回溯檢查。
實務上,建議把資料整理流程拆成幾個層次。第一層是文件層,也就是先配對「哪個英文文件對應哪個中文文件」。第二層是段落層,把每份文件拆成段落或條列項。第三層才是句子層,也就是為後續對齊預做準備。很多初學者一開始就想直接做句對,其實很容易卡住。因為如果連文件對應與段落切分都沒做好,句子層的錯誤會像雪球一樣擴大。先粗後細,通常比較穩。
另一個常被低估的問題,是locale。對英文來說,看似差異不大,但美式英文、英式英文、國際英文在用詞與格式上仍有差別;對中文來說,zh-TW、zh-HK、zh-CN的差異更明顯。譯者若以台灣為目標市場,就應盡可能優先蒐集繁體中文、用詞接近台灣慣例的資料。像「登入/登錄」、「資訊/信息」、「支援/支持」、「影片/視頻」、「帳號/賬號」這些差異,若在建置階段不先分開,後面匯入TM 或拿來做例句檢索時,就會造成風格污染與判斷混亂。
自行建語料不必從爬蟲或大型系統開始。實際的入門做法是選一個自己熟悉的領域,例如科技產品支援、文化展覽介紹、政府對外公告或教育平台文件,各自找出二十到五十組對應頁面,整理成表格,清理掉非正文內容,再做基本對齊與檢索。這種小規模專案最能幫助譯者建立資料感。便能開始注意到哪些網站的語言切換其實不是翻譯,哪些頁面看似平行其實只有一半內容對應,哪些固定欄位最好先刪除,哪些標題與小標可以拿來當對齊錨點。
若要更系統化評估某個網站是否值得納入自己的平行資料來源,可以先檢查五個指標。第一,看URL與語言切換邏輯是否穩定,例如英文與中文頁面是否有規律可循的對應路徑。第二,看更新節奏是否一致,避免英文已更新、中文仍停留在舊版。第三,看頁面是否保留標題階層、段落結構與條列清單,這些都會直接影響後續對齊難度。第四,看文字量是否以正文為主,而不是大量圖像、互動元件或嵌入式區塊。第五,看網站是否長期維護、連結穩定,因為臨時活動頁與短命專案頁通常很難形成可持續資源。
若從譯者的工作分工來看,適合建置成平行資料的網站,大致可以再分成三類。第一類是「術語穩定型」來源,例如官方技術文件、產品支援頁、標準作業說明、法規與政府公告。這類資料最適合做術語觀察、句型比對與TM累積。第二類是「風格觀察型」來源,例如博物館導覽、展覽介紹、品牌故事、公共溝通頁面。這類資料很適合觀察語氣與文案節奏,但不一定適合全部匯入TM。第三類是「工作流輔助型」來源,例如FAQ、知識庫、操作步驟、錯誤排除頁面。這類資料對UI、說明文與客服文本特別實用,且通常很適合做對照查詢。
一旦這種基本工做熟了,資料建置就不再只是技術工作,而是一種翻譯前置能力。便不再只是接到案件後臨時上網查,而是能在平時就為特定領域慢慢建立自己的素材庫。長期下來,這比單次查詢更有複利效果。因為每次清理好的資料,都可能在未來的查詢、對齊、術語擷取、TM??匯入與 AI 輔助工作中再次派上用場。
第四節 雙語對齊(bitext alignment)的基本概念
在取得一批大致對應的中英文文本後,下一步往往就是對齊。所謂bitext alignment,可以簡單理解成:在兩個語言版本之間,找出彼此對應的單位。這個單位可以大到整份文件,也可以小到段落、句子,甚至詞語。譯者在實務上最常碰到的,是文件層(document-level)、段落層(paragraph-level)與句子層(sentence-level)的對齊;而詞層對齊通常屬於更進階的自然語言處理,不一定是一般翻譯工作最優先需要掌握的。
很多人第一次接觸對齊時,會以為每一句英文都會對上一句中文。但真實世界並不是這樣。最理想的情況固然是一對一,也就是一個句子對應一個句子;但實務上還有很多一對多、多對一、多對多,甚至有省略與增補的情形。譬如英文原文為了節奏或可讀性,可能把兩個短句拆開;中文譯者為了符合中文行文習慣,可能把兩句合併成一個較長句。又或者,英文用一個長句堆疊修飾語,中文則拆成兩句甚至三句才自然。這些情況都會影響對齊。
以下是最常見的幾種對齊類型。第一,一對一。這是最容易理解也最容易匯入 TM的情況,例如:
You can reset your password on the account page. 你可以在帳號頁面重設密碼。 |
|---|
第二,一對多。例如英文原為一句,中文為了語氣自然而拆成兩句(以喬治.歐威爾《1984》開場白為例):
It was a bright cold day in April, and the clocks were striking thirteen. 四月裡,天氣晴朗寒冷。 |
|---|
第三,多對一。例如英文兩句,中文為了順句而合併:
Tap Save. 點一下「儲存」後,關閉對話方塊。 |
|---|
第四,是不完全對應。有些說明性插句、文化補充或法規聲明,在某一語言版本中可能被省略或改寫。這種情況如果硬要逐句對齊,通常只會製造更多噪音。
理解這些類型很重要,因為這些類型會直接影響如何看待平行資料。對齊不是在找機械對稱,而是在找可用對應。對譯者而言,「可用」通常比「完美對稱」更重要。假設目的是建立可做 concordance 查詢的雙語資料,那麼一對多或多對一其實未必是問題;只要中英對應關係仍清楚,就仍具有參考價值。但若目標為匯入CAT 工具當作 TM,則可能需要更嚴格的句段切分,以免後續模糊比對效果變差。
對齊之所以可行,通常依賴幾種線索。第一是結構線索,例如標題、章節編號、條列點、表格順序。第二是形式線索,例如數字、日期、專有名詞、括號、百分比、清單項號。第三是長度線索,雖然中英字數比例不固定,但大致仍有可參考的分布。第四是文脈線索,也就是前後句的語義連續性。很多半自動對齊工具就是把這些線索綜合起來估計哪些片段最可能對應。
但譯者要知道,長度線索只能輔助,不能當真理。因為中文與英文的壓縮率不同,中文往往較短;而且翻譯過程中可能發生重組、省略、增補與語序改寫。所以,如果某套工具只靠字數比例硬做對齊,結果常會在列表、表格、UI字串與短句資料中特別不穩定。真正可靠的對齊,通常還需要結合段落層資訊與人工抽樣檢查。
在實務流程上,對齊通常最好分三段進行。第一段是文件配對,先確定哪份英文文件對哪份中文文件。第二段是粗對齊,把大段落、章節、小標與條列結構先配好。第三段才是句對齊。這樣做的原因很簡單:如果文件層就配錯,或段落順序已經不一致,那麼句子層再精細也只是把錯誤放大。很多看似「對齊工具不好用」的情況,其實不是工具不行,而是上游資料沒有先整理好。
另外,句子切分(sentence segmentation)本身也會影響對齊品質。英文句子常以句點、問號、驚嘆號為界,但縮寫、版本號、網域名稱、程式碼片段又會干擾判斷。中文看似有句號、逗號、頓號、分號、冒號等標點,實務上卻常因標題、列表、UI片段與複製貼上造成切分不一致。如果一邊把項目符號後的內容切成獨立段,一邊把內容黏在前一句後面,對齊就會開始偏移。因此,對齊前先把切分規則盡量標準化,往往比直接找更複雜的演算法更有效。
對譯者而言,理解 bitext alignment還有一個更深的意義:這個概念提醒我們,平行資料不是天生就存在的,而是後製出來的。也就是說,任何取得的雙語句對,背後都隱含了一連串決策:這兩份文件是不是同一版?哪些段落算正文?標題要不要保留?表格與列表怎麼切?註腳算不算正文?若中文多了一段編按,怎麼處理?這些都不是純技術問題,而是資源建置的設計問題。
也因此,對齊品質要靠驗收。最常見的幾種錯誤包括:文件配錯版本、段落順序跑掉、標題被錯配到正文、導覽列與頁尾文字混進句對、列表項拆分不一致、日期與數字對應錯位、OCR錯字導致整句無法匹配、以及原本就是改寫關係卻硬被當作翻譯關係。這些問題若不抽樣檢查,很容易一路帶進後面的TM 與 AI 工作流,造成資源污染。
因此,一個實用的品質檢查原則是:不要只看高分匹配,要看低分可疑項。通常最值得人工檢查的,不是那些明顯一致的句對,而是長度差過大、數字不一致、標點結構怪異、或連續多句突然偏移的片段。很多工具可以先自動對齊,再把低信心片段標出來;若沒有工具,譯者也可以自己用簡單條件篩選,例如字數差太大、其中一邊空白、或只含短標籤文本的項目。
最後要強調的是,bitext alignment??的目的,不是追求理論上的完美,而是生成對當前任務有用的雙語資源。如果目的是進行查詢、術語觀察與風格比對,那麼適度容忍一對多、多對一的存在是合理的;若目的為匯入CAT 工具作為TM??,就應在匯入前進一步做句段修整,避免不必要的長句對與雜訊對。理解任務目的,決定對齊標準,這是譯者在面對平行資料時非常關鍵的判斷。
第五節 如何把自建資源接回 CAT 工作流程
自己建立雙語資料,如果最後只是躺在資料夾裡,價值其實有限。真正關鍵的是:這些資料能不能回到日常翻譯流程裡,變成能反覆使用的工作資產。對譯者而言,這通常意味著三件事:可以查、可以匯、可以維護。也就是說,資料不只要能在需要時快速檢索,還要能以某種格式匯入 CAT 工具,並在日後持續更新,而不是做完一次就報廢。
把自建資源接回 workflow之前,第一步不是匯出格式,而是先決定用途。因為不同用途,需要的資料結構不同。若你的目標是做對照查詢,那麼保留較完整的上下文、來源網址與文件層資訊就很重要。若目標為匯入TM,則需要更穩定的句段對應與較乾淨的文字內容。若欲擷取術語,則需要保留領域標記、文件類型與關鍵名詞的出現環境。很多資源之所以後來不好用,不是因為格式不對,而是一開始沒有釐清用途。
在譯者最常見的幾種輸出形式中,Excel 或 CSV通常是最容易入手的。對照表格最大的好處,是可視性高。可直接檢視每一列的英文、中文、來源、備註、領域、語區、信心水準、是否已人工驗證等欄位。這非常適合初期整理、抽樣校對與團隊協作。即使最後要匯入CAT工具,很多時候也會先經過表格階段,因為表格最方便篩選、排序、人工修補與標記問題。
若要更進一步與 CAT 系統接軌,TMX 幾乎是最標準的做法之一。TMX的價值,在於這種格式不是某個單一工具的私有格式,而是翻譯記憶交換格式。只要中英文句對夠乾淨,能明確標示語言方向與句段邊界,就有機會轉成TMX 再匯入各種 CAT工具。這時,自建語料就不再只是外部參考,而是能在翻譯時直接提供模糊比對、相符建議與既有譯法複用的內建資源。
不過,這裡有一個非常重要的原則:不是所有平行資料都適合直接變成 TM。TM的目標是可重用,因此特別怕髒資料。若將來源不明、對齊不穩、版本混雜、語區不一、風格差異過大的句對一股腦匯入,就會污染整個翻譯記憶庫。之後每次出現模糊比對時,工具都可能把這些品質參差的句段呈現於前,反而增加判斷成本。也就是說,TM不是語料資料夾的垃圾桶,而是高品質句對的精選區。
在建立專屬的雙語平行資料時,除了前述用於句段對齊的 TMX 之外,術語庫交換格式(TermBase eXchange, TBX)也是不可或缺的一環。如果說 TMX 是用來儲存與交換完整的翻譯句子,那麼 TBX 就是專門用來管理與交換「專業術語」與「詞彙表」(glossary)的國際標準 XML 格式。對於譯者而言,特定領域的專有名詞(人名、地名、機構名等)、客戶指定的譯法或縮寫,往往是確保翻譯品質與一致性的關鍵。透過 TBX 格式,譯者可以將散落於 Excel 表格、Word 檔案或不同 CAT 工具中的術語資料進行標準化整合。
掌握 TBX 的實務價值在於其「高度的跨平台相容性」與豐富的「詮釋資料」(metadata)。在建置雙語資源時,TBX 不僅能單純記錄中英對照的詞彙,還能容納詞性、定義、出處、例句,甚至是標註「禁用詞」(forbidden terms)等附加資訊。這意味著,無論未來更換哪一種翻譯軟體,或是需要與其他譯者及客戶協作,只要將精心整理的術語庫匯出為 TBX 檔,就能無縫轉移長期累積的領域知識,讓這些量身打造的詞彙資源發揮最大效應。
因此,建議把自建資源至少分成三層。第一層是原始資料層,保留尚未完全處理的文本與來源資訊。第二層是檢索層,以利進行全文搜尋、regex查找與對照查詢。第三層才是 TM層,只有經過人工抽樣檢查、語區一致、對齊品質穩定的資料才進來。這樣分層的好處,是無須將所有東西都塞進TM 才算「有用」。很多資料更適合當語料,而不是當記憶庫。
在 workflow中,自建雙語資料可以扮演至少四種角色。第一,專案前的準備資源。在開始翻譯前,先用自建資料做關鍵詞搜尋、風格探勘與術語盤點。第二,翻譯中的即時查詢資源。在CAT環境中遇到不確定的表達時,可以回到自建資料中做對照查詢。第三,審校與品質保證(quality assurance, QA)資源。完成譯稿後,可用既有資料比對相似句型與用語一致性。第四,專案後的資產回收。把這次專案中經客戶確認的譯法整理回資料庫,持續提升後續任務的起點。
若要讓資料真的可持續使用,命名與中介資料(metadata)非常重要。至少建議在每批資料上標明:語言方向、語區、領域、來源類型、時間區間、是否人工驗證、是否允許匯入TM。以台灣工作情境為例,把 en-US > zh-TW / 技術支援 / Apple Support / 2025Q4 / reviewed 這種標記保留下來,長期來看會比只存一個 tech_tmx.tmx有用得多。因為真正讓資源可管理的,不是檔名漂亮,而是清楚資料性質、從哪裡來、適合什麼場景。
此外,CAT workflow中最容易被忽略的一點,是方向性。英文到中文的句對,未必就適合反向作為中文到英文的主要依據。即使是平行資料,也要記得翻譯決策具有方向。某個中文句段能自然對應某英文句段,不代表在反向翻譯時仍會做出同樣切分與措辭。因此,匯入記憶庫時最好保留清楚的語言代碼與方向資訊,不要把所有中英片段都視為可任意雙向複用。
自建資源若要變成長期資產,還需要定期除污。所謂除污,包括刪除版本過時內容、移除低品質OCR 句對、合併重複資料、標記已棄用用詞、區分不同客戶或品牌的 style guide,並避免把明顯不該重用的材料一路保留。例如短期促銷文案、活動slogan、一次性公告、錯誤頁訊息的舊版本,都可能在某個時點失去重用價值。若不定期整理,資料庫只會越來越大,卻越來越不可信。
在這裡,Excel、TMX與其他格式之間其實不是互斥關係,而是不同層次的配合。很多譯者可以先用Excel 做整理與人工作業,等品質穩定後再匯出成 TMX 匯入CAT;同時又保留原始 HTML、TXT、ePub 或 Markdown檔作為檢索層。這種多層結構雖然看起來麻煩,但長期而言反而最穩。因為這種分層做法尊重不同格式的用途:表格適合管理、純文字適合搜尋、TMX適合 CAT。
若要把這件事具體化,可以把「從雙語網站到CAT」想成一條最小可行流程。第一步,挑選一組可信網站,先人工確認二十組中英文頁面是真正翻譯關係。第二步,保留原始HTML 或 PDF,另外抽出正文成為 raw_text。第三步,用 regex與人工檢查去掉導覽列、頁尾、重複標題與格式噪音。第四步,把每份文本依標題、段落、列表項切成較穩定的單位。第五步,再進入句子層對齊,並把可疑項標記為待驗證。第六步,把人工看過的一批高品質句對先放進Excel 或CSV,補齊來源、語區、領域與版本資訊。第七步,只有在這一批資料已經足夠乾淨時,才匯出成TMX 並導入 CAT工具。這條流程看起來保守,但優點在於每一層都能回頭修正,不會因為一次匯入就把污染擴散到整個工作環境。
很多譯者第一次嘗試自建 TM時,最大的問題不是技術,而是太早求快。若操之過急,往往會因句對品質不穩、語區混雜、來源不明,導致翻譯記憶庫在日後成為新的負擔。比較穩妥的做法,是把新建資源先當作「候選TM」,以獨立記憶庫或專用資料夾保存,經過一段時間的實際使用與修正,再決定是否併入主要TM。這種做法雖然慢一點,卻能有效保護既有資產,避免一時方便造成長期混亂。
若要把本節濃縮成一個 workflow思維,那就是:不要把語料、參考資料、TM、術語庫混成一團。彼此相關,但功能不同。語料擅長提供上下文與證據,TM擅長提供可重用句段,術語庫擅長提供規範化決策。自建資源最成功的狀態,不是全部塞進同一個桶子,而是讓各類資源在不同環節各自發揮作用,並且可以互相支援。
第六節 延伸討論:AI 代理人(AI agent)與未來翻譯工作流程
近年來,譯者接觸 AI 時,最常想到的是機器翻譯、大型語言模型(large language model, LLM)改寫或問答介面。但如果把焦點從「讓 AI直接直接進行翻譯」稍微移開,放到「讓 AI協助處理流程」上,會看到另一條很值得注意的路:AI代理人。所謂代理人(agent),不只是會回話的聊天介面,而是能在明確目標下,分步規劃、呼叫工具、執行任務、回報結果,甚至在某些框架中持續修正自己流程的系統。對語料建置而言,這種能力特別有潛力。
原因很簡單。建立雙語資料這件事,本來就不是單一步驟,而是一條鏈:找來源、抓頁面、抽正文、進行資料清理、標示語區、切段、對齊、抽樣檢查、匯出格式、產生日誌、回頭修規則。這條鏈上有大量重複、機械但又彼此相關的任務,非常適合交給能操作多個工具、保留中間狀態、並依規則執行的代理人。譯者在這裡的角色,也就不再只是最末端的文字處理者,而更像流程設計者與品質把關者。
(待補)
本章小結
本章從公開雙語語料庫談起,接著介紹關鍵詞檢索、對照查詢與正規表示式,再一路走到自建雙語平行資料、雙語對齊、CAT工作流程串接,以及 AI代理人的延伸應用。這幾個主題表面上分散,實際上都圍繞同一件事:譯者如何把零散文本轉化為可持續重用的資源。
若前兩章處理的是「如何把工具用好」,那麼本章處理的就是「如何讓工具不再只是一個操作介面,而成為資源循環的一部分」。當譯者能夠主動蒐集雙語網站、清理文本、進行對齊、建立可搜尋的例句庫,再把高品質句對整理回CAT 工具,翻譯工作就不再只是一次性的文字勞動,而是逐步累積的知識工程。
最重要的是,這條路並不要求每位譯者都成為工程師。真正需要的,是一種新的工作習慣:願意整理來源、願意保留metadata、願意用 regex 處理重複勞動、願意把語料與 TM 分層管理、願意在 AI agent 面前維持驗證與證據意識。做到這些,譯者就已經跨出了非常關鍵的一步。
未來的翻譯競爭力,越來越不只是語言能力本身,而是語言能力與資源能力、工具能力、流程能力如何結合。本章談的所有內容,正是這種結合的起點。
參考雙語網站示例
* OPUS:<https://opus.nlpl.eu>
* 外交部中文網站:<https://www.mofa.gov.tw/>
* 外交部英文網站:<https://en.mofa.gov.tw/>
* 國立故宮博物院:<https://www.npm.gov.tw/>
* Apple Support(中文-傳統漢字-台灣):<https://support.apple.com/zh-tw>
* MDN Web Docs(中文-傳統漢字-台灣):<https://developer.mozilla.org/zh-TW/>
參考工具示例
* Python官方文件(中文-傳統漢字-台灣):https://docs.python.org/zh-tw/
* Calibre ebook-viewer文件:https://manual.calibre-ebook.com/viewer.html
* OpenCode文件:https://opencode.ai/docs
* Google Antigravity: https://antigravity.google
* Google Gemini CLI: https://github.com/google-gemini/gemini-cli
* Zed editor: https://zed.dev
* TMXEditor: https://github.com/rmraya/TMXEditor
Footnotes
華語地區通常直接使用英語 concordance??↩︎